리눅스의 특징은 모든 데이터를 파일로 표현한다.
I-node란 Index Node의 줄임말로
Index: 색인 = 어떤 내용을 빨리 찾아보기 위해 일정한 순서로 정리한 목록
Node : 데이터의 지점이나 장치 = 데이터를 갖고 있는, 디스트의 한 지점이나 컴퓨터, 휴대폰, 프린트같은 장치들을 노드라 한다.
i-node : 데이터를 갖고있는것을 빠르게 찾기 위해 순서대로 정리한 정보
ls -l을 치면 i-node를 볼 수 있는데
drwxr-xr-x 2 root root 7 7월 31 15:27 이런 형식을 띔
앞에서부터 파일형식 / 파일권한 / 링크수 / 파일 소유주 / 파일 그룹 / 파일크기 / 파일이 만들어진 시간임
리눅스에서는 파일이 생성될 때 i-node도 같이 생성되고 i-node list table이라 불리는 i-node를 모아두는 곳이 있습니다.
테이블에서 i-node를 구분하기 위해 각 i-node엔 번호가 붙어있음. (ls -i 옵션으로 볼수 있음)
리눅스 파일 종류
리눅스에서는 모든 데이터를 파일로 표현함. 그렇기에 리눅스 파일은 특수파일, 디렉토리 파일, 일반 파일, 링크 파일 이렇게 4가지로 나눌 수 있음.
- 특수파일
특수파일에는 파이프, 주변장치, 소켓 같은 것들이 있음. | 이렇게 생긴 특수기호가 파이프임
소켓은 프로그램이 서버와 통신을 할 때 네트워크 접속을 위한 연결장치 역할을 하는 소프트웨어임.
파일형식 7개 중 4개가(b,c,p,s) 특수 파일임.
b: 블록형 특수 장치파일 (디스크파일인 /dev/sda 같은 것)
c: 문자형 특수 파일 (입출력에 사용하는 콘솔 /dev/console 같은 것)
p: 파이프 특수 파일
s : 소켓 특수 파일
윈도우에서는 디스크를 'C:', 'D:' 이렇게 표기한다면 리눅스에서는 /dev/sda , /dev/sdb .. 이런식으로 끝의 알파벳이 증가하는 식으로 디스크 파일 형식이 표기됨.4
'sda1', 'sda2' 이런 숫자는 파티션임
파티션이란 'partition'이란 영어 그대로 'sda란 드라이브를' sda1, sda2 이렇게 2개로 나눈것으로 보면 됨
리눅스에서는 디스크 외에도 디바이스도 모두 특수 파일 취급함
- 디렉토리 파일
보통 줄여서 '디렉토리'라 부르지만 굳이 따지자면 '디렉토리 파일'이 맞음.
디렉토리의 특징은 윈도우 폴더처럼 트리형식으로 안에 다른 파일들을 가질 수 있음.
트리구조란 상위폴더가 하위폴더를 또 하위폴더가 다른 하위폴더를 가지고 있는 구조를 일컬음
디렉토리와 파일의 구분은 i-node를 통해 할 수 있음.
- 일반파일
데이터를 관리하는데 주로 사용되는 일상적인 파일 대부분이 일반 파일임.
일반파일은 i-node의 맨앞이 '-'로 표시됨
'실행 파일'이나 '이미지 파일'의 경우 데이터가 '바이너리' 형태로 저장되어 있기 때문에 텍스트 파일 읽을 때 처럼 'cat'나 'vi' 명령어로 읽을 수 없음
바이너리 파일을 구분을하는 방법은 file 명령어를 이용하면 됨
- 링크파일
이름 그대로 "링크(연결)" 역할을 하는 파일로서 종류엔 소프트일크와 하드링크가 있음.
소프트링크는 바로가기 같은 것이고 하드링크는 원본과 연결된 똑같은 파일임.
리눅스에서는 특별한 확장자를 나타내는 이름같은 것이 없음
그렇기에 리눅스에서는 파일의 이름만 봐도 용도를 알 수 있게 이름을 짓음.
리눅스에서 'cd /etc'라는 명령어로 /etc/디렉토리에 들어가 ls로 파일을 확인해보면
파일끝에 .conf .cfg .d로 붙은 것들이 보임
.conf, .cfg는 configuration(설정)의 약어임.
repos는 repository의 약어
.d는 directory의 약어
- 파일시스템이란
컴퓨터에서 파일이나 자료를 쉽게 발견 및 접근할 수 있도록 보관 또는 조직하는 체제
- 클러스터, 블록 등장 배경
첫 번재 문제는 큰 파일의 데이터들을 읽고 쓰는데 느린다는 것이다. 데이터를 나눠 기록하는 하나의 섹터들의 크기는 보통 512바이트이다. 예로 크기가 10mb인 파일을 사용한다 치면 디스크에서 메모리로 2*1024*10개의 섹터를 불러와야 한다. 컴퓨터 기술로 발전으로 사용하는 파일의 크기도 커지기 시작해 문제가 된다.
이것들을 해결하기 위해 도입된 기술이 "섹터들을 한 번에 여러개를 읽는 것"이다.
섹터(512바이트)씩 파일의 정보를 나눠 저장하고 읽어 들이기 보다, 2개씩, 4개씩 묶어서 읽고 저장하는 것이다.
이렇게 섹터들을 묶는 단위를 클러스터 또는 블록이라 함
묶어서 보낼때 마지막에 빈 공간이 남게 되는데, 이렇게 낭비되는 현상을 슬랙 공간이라고 함.
운영체제를 공부하다 보면 클러스터와 블록이라는 말을 혼용해서 접하게 되는데 이 둘의 차이는 없음.
클러스터, 블록 이란 단위를 계산해주는 것도 결국은 파일시스템의 역할 중 하나임.
- 효율적으로 디스크에 데이터를 관리해주는 파일시스템
기존 실린더 방식 데이터 보관의 두 번째 문제는, 디스크에 데이터를 실제로 저장하고 사용할 때 능률이 매우 떨어집니다.
기존 파일이 저장돼있다가 수정을 통해 크기가 줄거나 삭제됐을 떄 섹터의 빈공간을 생겨 공간이 낭비되게 된다. 그게 세번째 문제이다.
이러한 문제들을 해결하기 위해 파일시스템이 도입되었음.
파일시스템의 역할
- 데이터를 더 빠르게 읽고 저장할 수 있는 단위 블록을 소프트웨어적으로 계산해준다.
- 분산 저장된 연관된 데이터들을 빠르게 찾게 해준다.
- 디스크 조각모음과 같이 디스크 공간을 효율적으로 사용하게 해준다.
저 세 가지를 어떤 방식으로 하냐에 따라 파일시스템의 종류가 달라지게 됨.
주소 지정 방식의 CHS, LBA
CHS 방식은 실제 물리적인 디스크 위치를 고려한 물리적 주소 지정 방식임
플래터 중앙으로 갈 수록 물리적으로 한 트랙 내 섹터의 수는 외부쪽에 비해서 적어지기 때문에 디스크 주소지정에서의 혼돈을 막기 위해, 수가 적은 내부쪽 섹터의 수로 통일해서 CHS를 계산하게 됨.
이로인한 문제는 실제 디스크 용량보다 더 적게 사용할 수 밖에 없음.
문제를 해결하기 위해 LBA, 논리적으로 주소를 계산하게 했음.
LBA는 논리적으로 모든 섹터를 한줄로 구현해 실제 위치와 상관 없이 모든 섹터를 순서대로 주소를 지정해 계산하는 것임.
LBA 주소 지정 방식은 지금까지도 사용되는 주소 지정 방식임.
실제 디스크 섹터 위치 ←→ 논리적 섹터 위치를 바꿔주는 것이 BIOS임.
Basic(직접적으로) Input/Output(하드웨어의 입출력을 제어하는) System(소프트웨어)
기존 컴퓨터의 하드웨어와 소프트웨어 상호작용은 BIOS를 통해 가능
하드웨어 ↔ BIOS ↔ 소프트웨어(운영체제)
파일시스템의 추상화 구조
대부분의 파일시스템은 데이터를 저장할 때 메타 지역과 데이터 지역으로 나눠 저장해 관리함.
데이터 지역은 유저 데이터라고도 하여 우리가 생각하는 대부분의 데이터를 저장하는 공간임.
메타 지역은 자기가 가진 특징을 가리키는 데이터임
메타 데이터란 리눅스의 I-node라고 보면 됨.
파일시스템의 종류와 역사
파일시스템은 저장공간을 사용한다면 무조건 필요한 소프트웨어이며 운영체제에 무조건 필수적으로 포함 되야함을 알 수 있음.
USB에서 자주 사용되는 파일시스템 FAT(file Allocation Table)16, 32가 있고
윈도우 운영체제에 사용되는 파일 시스템은 NTFS(New Technology File System)
리눅스 운영체제에 사용되는 파일 시스템은 ext2, ext3, ext4, xfs가 있음.
먼저 FAT같은 경우
리눅스 SWAP 메모리
SWAP메모리란 물리메모리가 부족한 경우를 대비해 만들어 놓은 공간입니다. 메모리는 프로세스에서 요청하는 연산을 위해 존재하는데 물리메모리 공간이 작을 시 프로세스 멈춤현상이 발생합니다. 이런 이슈를 대비하기 위해 비상용으로 확보해 놓은 메모리가 SWAP입니다.
윈도우에서는 디스크 순서를 C → D → E 이런식으로 이어집니다. 반면, 리눅스에서의 디스크는 '/dev'디렉토리 안에 sda,sdb,sdc... 이렇게 이루어 진다 여기서 'sda1', 'sda2' 이런 숫자가 붙은 것은 파티션을 의미합니다. 파티션이랑 영어 'partition'의 뜻 그대로 'sda란 드라이브'를 'sda1, sda2'이렇게 나눈것이라 보면 됩니다.
LVM (Logical Volume Manager)
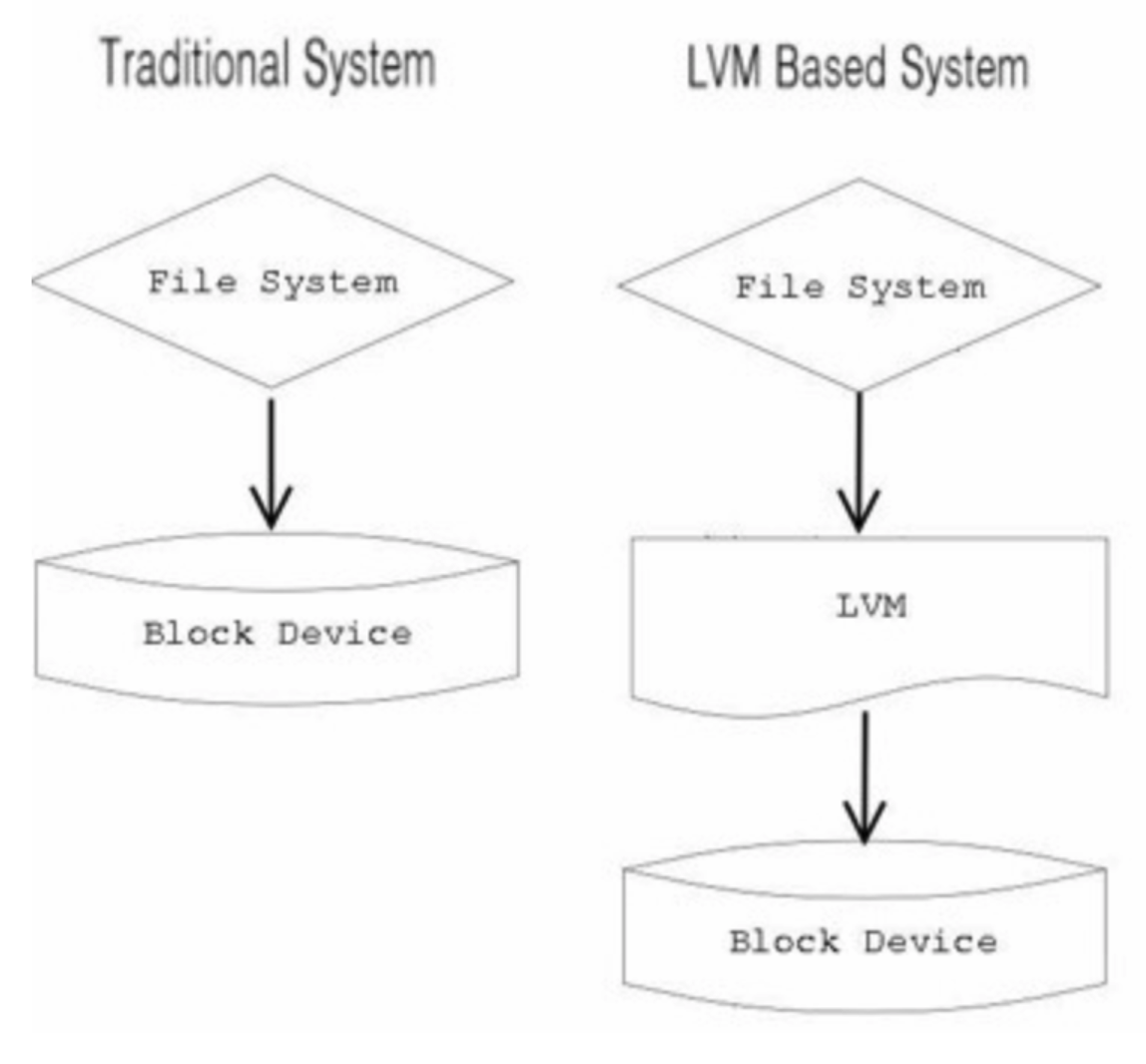
lvm : https://kit2013.tistory.com/199
$ lsblk : 블록디스크 구성 목록
Logical Volume을 효율적이고 유연하게 관리하기 위한 커널의 한 부분이자 프로그램
기존: 파일시스템을 블록 장치에 직접 접근해서 쓰는 방식
LVM: 파일시스템이 LVM을 통해 만들어 놓은 가상의 블록 장치에 읽고 쓰는 방식.
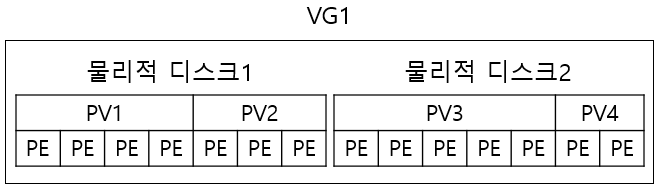
PV(Physial Volume): LVM에서 블록 장치를 사용하려면 PV로 초기화를 해야한다. 즉, 블록 장치 전체 또는 그 블록 장치를 이루고 있는 파티션들을 LVM에서 사용할 수 있게 변환한것이다. 예를 들어 /dev/sda1, /dev/sda2 들을 LVM으로 쓰기위해 PV라는 형식으로 변환한 것이다. PV는 일정한 크기의 PE(Physial Extent)들로 구성이 된다.
*블록 장치 : 블록 단위로 접근하는 스토리지. 예) 대용량 하드 디스크
Uploaded by
N2T'CS 기초' 카테고리의 다른 글
| SSH (0) | 2023.03.20 |
|---|---|
| AppArmor & apt (0) | 2023.03.20 |
| LVM (0) | 2023.03.20 |
| Debian vs CentOS (0) | 2023.03.20 |
| 가상머신 (0) | 2023.03.20 |

